Author(s): Laura Greenstreet is currently a PhD student at Cornell University where she works on developing AI and optimization methods with sustainability applications.
Introduction
Computational sustainability is an emerging field which uses computational ideas and methods to address the United Nations Sustainable Development Goals (UN SDGs). While the term sustainability is commonly associated with environmental sustainability, the UN SDGs take a wider view, defining sustainable development as meeting environmental, social, and economic needs both now and in the future [1]. The 17 goals include alleviating hunger and poverty, access to healthcare and education, climate action and biodiversity preservation, and decent work and economic growth. The SDGs were adopted in 2015 with a target date of 2030, where progress is tracked through annual reports and comprehensive reviews conducted every four years.
The SDGs are the successors to the Millennium Development Goals (MDGs), which showcase the benefits of international cooperation, planning, and monitoring. While not all MDGs were fully met, significant progress was made, including halving the portion of people in extreme poverty and reducing the under-five mortality rate by half [2]. However, the gap on some goals, such as ensuring environmental sustainability, widened and recent reports show new gaps emerging, such as increasing food insecurity related to the conflict in the Ukraine [3].

How can AI Help Address the SDGs?
The SDGs highlight some of the most pressing issues for creating a future that is sustainable and equitable economically, socially, and environmentally. The global and interconnected nature of the goals creates challenges that are not addressed well by traditional approaches to development, creating opportunities for innovation in how to measure targets and impacts, maximize the benefit of limited resources, and improve and develop new technologies. Computational methods and ideas have the potential to scale existing methods as well as create new approaches.
However, computational sustainability does not just benefit sustainability domains. The scale and complexity of sustainability problems highlights limitations in existing computational methods and motivates new approaches to address problems like noisy and biased data or shifting distributions. Further, core computational problems often arise that apply to multiple domains, leading to general computational solutions. For example, source separation problems arise in sustainability domains ranging from identifying birds calls in real-world audio [4] to identifying novel compounds from X-ray diffraction data [5].
The broad scope of the SDGs leads computational sustainability to touch on many areas both within computer science and from other disciplines, as well as intersect with many computation for good communities. While specialized knowledge is critical for addressing computational sustainability problems, common problems and core computational ideas lead to benefits from sharing ideas and collaborating across disciplines. Thus the field of computational sustainability complements specialized communities, helping develop general methodologies that advance both computational disciplines and the Sustainable Development Goals.
In the next section, we’ll highlight examples of successful computational sustainability projects that relate to three commonly occurring challenges:
-
Dealing with missing or incomplete data
-
Dealing with biased, noisy, or shifting data distributions
-
Incorporating AI into the decision making process
Examples
Dealing with Missing or Incomplete Data
Often the data that would be most useful for addressing computational sustainability problems is not available or is incomplete. Traditional data collection methods like censuses and scientific surveys are not scalable due to effort and cost and cannot be done with enough frequency to be used for time-sensitive tasks like disaster response or forecasting. AI can help scale and automate data collection as well as creatively leverage existing data sources for new tasks.
Mapping and Monitoring Poverty from Satellite Data
Local economic measures are needed to assess and inform policy on SDGs such as poverty, health, education, and hunger. However, there is often a lack of recent data with high spatial resolution. Censuses are one of the best sources of this information, but they are difficult to compare across regions and are at most conducted every few years. In developing regions, censuses may be even more infrequent. From 2000-2010, 14 of 59 African countries did not conduct a single census with questions that could inform poverty measures [6]. However, simply scaling existing efforts is prohibitively costly, with cost estimates for scaling existing methods to measure every SDG over a 15 year period are in the hundreds of billions of dollars for African countries alone [6].
There are many open source remote sensing datasets that provide good spatial and temporal coverage. For example, the Sentinel satellites launched in 2014 provide 10-30m resolution images with a revisit time as low as 5 days, leading to more than 50 images of every location on earth each year [7]. However, it not obvious how to go from satellite imagery to indicators useful for achieving the SDGs.
Jean et al. [6] developed a transfer learning approach to train a CNN to identify features that explain economic variation at a local level with only hundreds of economic surveys. The model was first trained to recognize nightlights, a noisy proxy for poverty with abundant labels [8, 9]. The model was then fine-tuned to estimate household-level assets at a local level. The model performed better than using nightlights alone or and even more difficult to obtain proxies like cellphone usage [10]. Further, the model explained a similar amount of variation as traditional, less scalable approaches like surveys [11] and the results of the model are now used by the World Bank [12]. Two desirable aspects of this method are that is uses only open source data and that it provides a general methodology that could be applied to other mapping tasks.
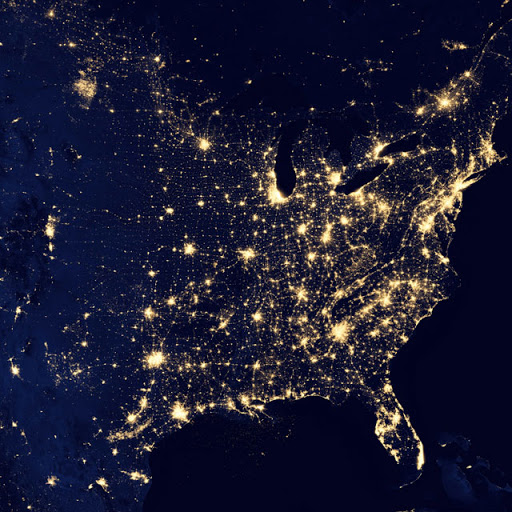
Figure 1: Nightlights are a noisy proxy for economic indicators that help measure progress towards the SDGs. Researchers at Stanford developed a model that starting from nightlights learns features that predict economic variation as effectively as on-the-ground approaches like surveys. Image source: Google Earth
There are many other examples of projects finding impactful ways to use remote sensing data including crop yield prediction [13], factory farm detection [14], and disaster response [15]. Outside of remote sensing, creating conservation datasets from audio recordings [16,17] and citizen science data, covered in more detail below, are exciting approaches for creating and improving datasets.
Dealing with Biased, Noisy, and Shifting Data
In many cases, complete data cannot be collected or the distribution of data actively changes over time. Further, data collection methods often introduce bias and some samples may even have incorrect labels. Many AI and machine learning methods assume correct labels and that examples represent i.i.d. samples from a static distribution. This creates the need for methods that can handle biased, noisy, and shifting data distributions.
Avicaching: Reducing Bias in Citizen Science Data
An exciting data source for biodiversity and conservation is citizen science data. Traditionally, observations of species were conducted through scientific surveys, creating small datasets that often only record a subset of species. Individual surveys cover small areas at a single point in time and require expert scientists, limiting their scalability. Citizen science initiatives like eBird [18] and iNaturalist [19] allow anyone to report observations, leveraging a combination of AI and online communities to label observations. These initiatives have collected vast datasets where new observations are continuously added, creating the opportunity to detect trends over time. However, observations are biased by a variety of factors including what species participants choose to report and where participants choose to make observations.
Xue et al. [20] introduced Avicaching, a two-stage game that designs incentives to encourage citizen scientists to collect more uniform data. The method uses a structural SVM to estimate the utility of locations as well as develops a scalable optimization framework that embeds the goal of participants within the problem of the organizer to make optimization tractable. A notable aspect of this project is that the authors recognized that the participants’ problem could be reduced to an instance of the well-studied knapsack problem [21]. This allowed them to use several previously developed approximations as well as made their framework applicable to a broader class of problems. By partnering with eBird, Avicaching was tested in two counties in New York state and was found to significantly shift birder behaviour, where during the three month trial 20% of observations occurred in areas with no prior observations [20].

Deep Hurdle Networks for Zero-Inflated Data
While methods like Avicaching can help collect more uniform data, other biases will still impact the data. For example, a species that is present in an area may not be reported because it requires expert skills to identify or may only be observable during certain times of the day or weather conditions. This leads to incorrect zeros in observation data. Multi-variate probit models (MVPs) are popular models for understanding species interactions [22]. Kong et al. [23] developed a deep hurdle network for multi-species abundance estimation that separately models the abundance of a species using a deep multi-variate probit model (DVMP) [24] and whether the ‘hurdle’ of a species being observed is crossed to account for zero-inflation. These models are connected by a shared covariance matrix and are integrated into an end-to-end deep learning model which can efficiently be trained on GPUs, unlike classic MVPs which require sequential steps. On the eBird dataset, the model achieved nearly 10% higher accuracy than the next best method and ran in less than a quarter of the time than the prior state-of-the-art. This example highlights that prior methods can provide the foundation for new computational sustainability methods, where limitations in current methods, such as scalability or assumptions about the data, are the motivation for new computational ideas.
Other projects addressing biased, noisy, or shifting data include crop yield prediction [13], anomaly detection in weather sensors [25], and methods for domain generalization with applications including conservation, agriculture, and health [26,27,28].
Incorporating AI into Decision Making
An exciting direction in computational sustainability research is incorporating AI into the decision making process. Decision tasks can take a variety of forms, including allocating limited resources or making decisions based on multiple conflicting objectives. Many traditional approaches to decision making are not scalable, make strong assumptions, or struggle to handle incomplete or uncertain data.
While there is great potential to combine AI and decision making, there are also significant challenges. A common challenge in combining AI methods like deep learning into decision making problems is implementing hard, discrete constraints. While there are methods that can handle discrete or hard constraints, they often face challenges in scalability or require specific problem structures. A second common challenge is integrating modelling and decision making. Parameters for the optimization component of a decision problem are often predicted using models. However, many optimization methods do not take into account uncertainty in the parameters due to imperfect prediction models.
Predict then Optimize to Improve Maternal Health Outcomes
Initiatives often have limited resources and want to design programs to maximize impact. For example, the non-profit ARMMAN operates maternal health programs in India that provide expecting and new mothers with health information through automated calls [29]. While some mothers drop out of the program, some will reengage with the program if visited by a health worker. However, as the program serves over 2 million participants, ARMMAN only has the resources to visit a fraction of the mothers in the program.

Biwas et al. [29] designed a model to prioritize mothers to visit, modelling the problem as a restless multi-arm bandit problem. The authors found that previous work required an uncertainty model to be known a priori. However, these values would be difficult to approximate from existing data and were not expected to follow a particular distribution. Instead of estimating the parameters before the optimization or introducing strong assumptions, the authors developed a version of the prior Q-learning algorithm that simultaneously learned the values for the uncertainty model and the best strategy for contacting mothers. The authors proved the model converges to the optimal solution and demonstrated that it outperforms existing methods on several datasets. Further, the authors worked with ARMMAN to test the method in practice, finding the method was over 30% more effective in preventing drop out than baseline methods [30].
An important aspect of this project is that the researchers worked with collaborators to solve an ongoing problem, working to develop an approach that would be feasible with available resources and data and testing the method in practice. While it is often the intent that research will be applied in practice, it takes concerted effort and time to build collaborations and take ideas from a model or publication to a real-world implementation. In fact, all of the examples described here involved collaborations between computer scientists and domain experts and often took years to go from initial questions to real-world demonstrations.
Other examples of incorporating AI into decision making include efficient multi-objective optimization to for hydropower dam planning [31], using a combination of game theoretic methods and reinforcement learning to combat poaching[32], and power grid optimization [33].
Computational Themes
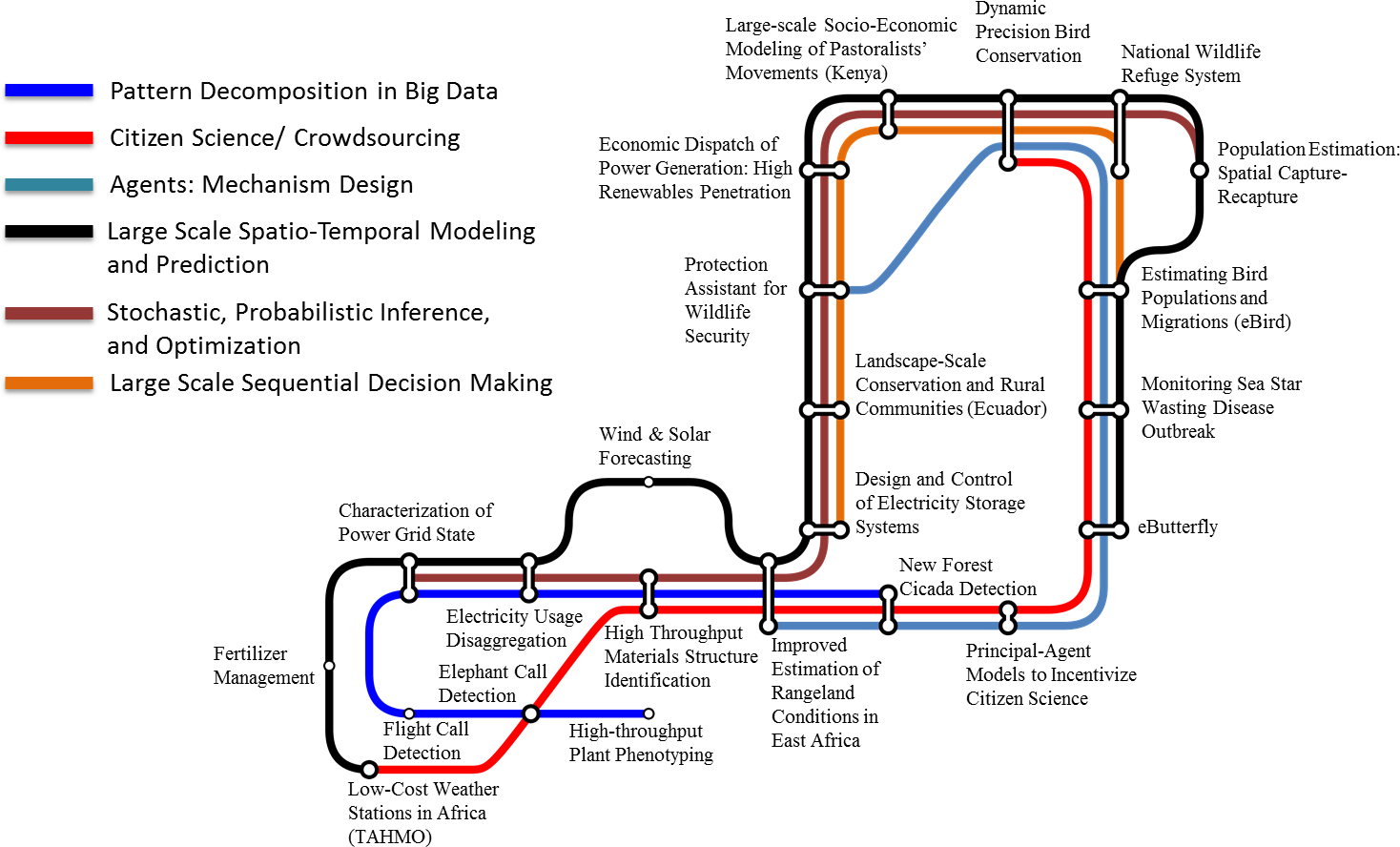
In addition to the common challenges outlined here, there are many computational themes that connect projects from disparate domains. Gomes et al. [12] use the metaphor of subway lines and stations, where projects are stations that are connected by themed subway routes. These common themes highlight the potential benefits of sharing ideas across the computational sustainability community and developing general computational methods that can be applied to multiple problems.
Getting Involved
There are many ways to get involved in computational sustainability, depending on your background and desired level of involvement. First, while this post only had the space to highlight a few examples, there is a wide variety of computational sustainability research. The readings in the resource section are a good place to learn more about successful projects and open research problems. Many top AI and data science conferences have added sustainability or AI for good tracks or workshops in recent years and their proceedings are also a good resource to learn about active research areas. There are also several communities related to sustainable development that share information about seminars, workshops, conferences and funding opportunities as well as provide opportunities to interact with the community and build collaborations. Several of these communities offer ways to help individuals with either computational or domain experience get more involved in computation for good including Climate Change AI’s summer school and the Data Science for Social Good summer fellowship programs hosted at universities around the globe.
Finding and formulating computational sustainability problems is often a challenging and iterative process and greatly benefits from having both computational experts and domain specialists involved throughout. The article Becoming good at AI for Good [34] provides a good summary of some of the challenges doing research with social impacts as well as has suggestions for creating successful collaborations. While strong collaborations are often a key part of successful projects, the community has also created more accessible entry points through competitions and benchmark tasks. DrivenData runs Kaggle-like competitions focused on AI for good and many organizations will create community competitions on Kaggle related to the SDGs, from identifying species in citizen science images to predicting air quality levels. There are also several collections of datasets that can be used for a variety of problems including SDGs Today that includes a variety of continuosly updated spatial datasets related to the SDGs and Datasets for Good which complies datasets, tutorials, and challenges.
We hope through this post you have gained a better understanding of computational sustainability as well as the resources available to become involved in the community!
Resources
Readings
-
Computational Sustainability: Computing for a Better World and a Sustainable Future [12]
-
The Role of Artificial Intelligence in Achieving the Sustainable Development Goals [36]
Communities
Conferences and Workshops
-
COMPASS - ACM Conference on Computing and Sustainable Societies
-
AAAI Fall 2023 Symposium: The Role of AI in a Climate-Smart Sustainable Future
Benchmarks and Datasets
References
[1] United Nations. UN Sustainability Development Goals.
[2] United Nations. UN Millenium Development Goal Fact Sheets, 2013.
[3] Statistics Division, Department of Economic and Social Affairs. Sustainable Development Goals Progress Chart 2022. Technical report, United Nations, 2022.
[4] Stefan Kahl, Connor M Wood, Maximilian Eibl, and Holger Klinck. Birdnet: A deep learning solution for avian diversity monitoring. Ecological Informatics, 61:101236, 2021.
[5] Junwen Bai, Yexiang Xue, Johan Bjorck, Ronan Le Bras, Brendan Rappazzo, Richard Bernstein, Santosh K Suram, Robert Bruce Van Dover, John M Gregoire, and Carla P Gomes. Phase mapper: Accelerating materials discovery with ai. AI Magazine, 39(1):15–26, 2018.
[6] Neal Jean, Marshall Burke, Michael Xie, W Matthew Davis, David B Lobell, and Stefano Ermon. Combining satellite imagery and machine learning to predict poverty. Science, 353(6301):790–794, 2016.
[7] ESA Sentinel. Msi user guide. Available online: Sentinel. esa. int/web/sentinel/user-guides/document-library (accessed on 12 June 2023), 2.
[8] Xi Chen and William D Nordhaus. Using luminosity data as a proxy for economic statistics. Proceedings of the National Academy of Sciences, 108(21):8589–8594, 2011.
[9] Maxim Pinkovskiy and Xavier Sala-i Martin. Lights, camera. . . income! illuminating the national accounts-household surveys debate. The Quarterly Journal of Economics, 131(2):579–631, 2016.
[10] Joshua Blumenstock, Gabriel Cadamuro, and Robert On. Predicting poverty and wealth from mobile phone metadata. Science, 350(6264):1073–1076, 2015.
[11] Christopher Yeh, Anthony Perez, Anne Driscoll, George Azzari, Zhongyi Tang, David Lobell, Stefano Ermon, and Marshall Burke. Using publicly available satellite imagery and deep learning to understand economic well-being in africa. Nature communications, 11(1):2583, 2020.
[12] Carla Gomes, Thomas Dietterich, Christopher Barrett, Jon Conrad, Bistra Dilkina, Stefano Ermon, Fei Fang, Andrew Farnsworth, Alan Fern, Xiaoli Fern, et al. Computational sustainability: Computing for a better world and a sustainable future. Communications of the ACM, 62(9):56–65, 2019.
[13] Anna X. Wang, Caelin Tran, Nikhil Desai, David Lobell, and Stefano Ermon. Deep transfer learning for crop yield prediction with remote sensing data. In Proceedings of the 1st ACM SIGCAS Conference on Computing and Sustainable Societies, COMPASS ’18, New York, NY, USA, 2018. Association for Computing Machinery.
[14] Caleb Robinson, Ben Chugg, Brandon Anderson, Juan M Lavista Ferres, and Daniel E Ho. Mapping industrial poultry operations at scale with deep learning and aerial imagery. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 15:7458–7471, 2022.
[15] Ethan Weber and Hassan Kané. Building disaster damage assessment in satellite imagery with multi-temporal fusion. arXiv preprint arXiv:2004.05525, 2020.
[16] Johan Bjorck, Brendan H Rappazzo, Di Chen, Richard Bernstein, Peter H Wrege, and Carla P Gomes. Automatic detection and compression for passive acoustic monitoring of the african forest elephant. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 476–484, 2019.
[17] Cornell Lab of Ornithology. Merlin bird id. Available online: https://merlin.allaboutbirds.org/ (accessed on 20 June 2023).
[18] Brian L Sullivan, Jocelyn L Aycrigg, Jessie H Barry, Rick E Bonney, Nicholas Bruns, Caren B Cooper, Theo Damoulas, André A Dhondt, Tom Dietterich, Andrew Farnsworth, et al. The ebird enterprise: An integrated approach to development and application of citizen science. Biological conservation, 169:31–40, 2014.
[19] iNaturalist Network. inaturalist. Available online: https://www.inaturalist.org (accessed on 20 June 2023).
[20] Yexiang Xue, Ian Davies, Daniel Fink, Christopher Wood, and Carla P Gomes. Avicaching: A two stage game for bias reduction in citizen science. In Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems, pages 776–785, 2016.
[21] Richard M Karp. Reducibility among combinatorial problems. Springer, 2010.
[22] JR Ashford and RR Sowden. Multi-variate probit analysis. Biometrics, pages 535–546, 1970.
[23] Shufeng Kong, Junwen Bai, Jae Hee Lee, Di Chen, Andrew Allyn, Michelle Stuart, Malin Pinsky, Katherine Mills, and Carla P Gomes. Deep hurdle networks for zero-inflated multi-target regression: Application to multiple species abundance estimation. arXiv preprint arXiv:2010.16040, 2020.
[24] Di Chen, Yexiang Xue, and Carla Gomes. End-to-end learning for the deep multivariate probit model. In International Conference on Machine Learning, pages 932–941. PMLR, 2018.
[25] Tadesse Zemicheal and Thomas G Dietterich. Anomaly detection in the presence of missing values for weather data quality control. In Proceedings of the 2nd ACM SIGCAS Conference on Computing and Sustainable Societies, pages 65–73, 2019.
[26] Sara Beery, Elijah Cole, and Arvi Gjoka. The iwildcam 2020 competition dataset. arXiv preprint arXiv:2004.10340, 2020.
[27] Etienne David, Simon Madec, Pouria Sadeghi-Tehran, Helge Aasen, Bangyou Zheng, Shouyang Liu, Norbert Kirchgessner, Goro Ishikawa, Koichi Nagasawa, Minhajul A Badhon, Curtis Pozniak, Benoit de Solan, Andreas Hund, Scott C. Chapman, Frederic Baret, Ian Stavness, and Wei Guo. Global wheat head detection (gwhd) dataset: A large and diverse dataset of high-resolution rgb-labelled images to develop and benchmark wheat head detection methods. Plant Phenomics, 2020, 2020.
[28] Peter Bandi, Oscar Geessink, Quirine Manson, Marcory Van Dijk, Maschenka Balkenhol, Meyke Hermsen, Babak Ehteshami Bejnordi, Byungjae Lee, Kyunghyun Paeng, Aoxiao Zhong, et al. From detection of individual metastases to classification of lymph node status at the patient level: the camelyon17 challenge. IEEE Transactions on Medical Imaging, 2018.
[29] Arpita Biswas, Gaurav Aggarwal, Pradeep Varakantham, and Milind Tambe. Learning index policies for restless bandits with application to maternal healthcare. 2021.
[30] Aditya Mate, Lovish Madaan, Aparna Taneja, Neha Madhiwalla, Shresth Verma, Gargi Singh, Aparna Hegde, Pradeep Varakantham, and Milind Tambe. Field study in deploying restless multi-armed bandits: Assisting non-profits in improving maternal and child health. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 12017–12025, 2022.
[31] Xiaojian Wu, Jonathan Gomes-Selman, Qinru Shi, Yexiang Xue, Roosevelt Garcia-Villacorta, Elizabeth Anderson, Suresh Sethi, Scott Steinschneider, Alexander Flecker, and Carla Gomes. Efficiently approximating the pareto frontier: hydropower dam placement in the amazon basin. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
[32] Lily Xu. Learning, optimization, and planning under uncertainty for wildlife conservation. INFORMS Doing Good with Good OR, 2021.
[33] Priya L Donti, David Rolnick, and J Zico Kolter. Dc3: A learning method for optimization with hard constraints. arXiv preprint arXiv:2104.12225, 2021.
[34] Meghana Kshirsagar, Caleb Robinson, Siyu Yang, Shahrzad Gholami, Ivan Klyuzhin, Sumit Mukherjee, Md Nasir, Anthony Ortiz, Felipe Oviedo, Darren Tanner, et al. Becoming good at ai for good. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, pages 664–673, 2021.
[35] David Rolnick, Priya L Donti, Lynn H Kaack, Kelly Kochanski, Alexandre Lacoste, Kris Sankaran, Andrew Slavin Ross, Nikola Milojevic-Dupont, Natasha Jaques, Anna Waldman-Brown, et al. Tackling climate change with machine learning. arXiv preprint arXiv:1906.05433, 2019.
[36] Ricardo Vinuesa, Hossein Azizpour, Iolanda Leite, Madeline Balaam, Virginia Dignum, Sami Domisch, Anna Felländer, Simone Daniela Langhans, Max Tegmark, and Francesco Fuso Nerini. The role of artificial intelligence in achieving the sustainable development goals. Nature communications, 11(1):1–10, 2020.