Manifesto
In recent years, AI has almost been everywhere, from our daily life to life-critical systems. AI for science is a new terminology representing a growing community that attracts more and more people from both AI and science communities to work on scientific discovery with AI. You may wonder what AI really is? How AI for science works? How is it related to my daily work? In this blog, we introduce AI to people who are interested in AI for science (especially from the view of the scientific community) and answer the above questions, including what AI brings to the scientific community, successful examples of AI in scientific applications, AI mindsets in tackling different types of scientific problems.
News you may hear about AI
-
DeepBlue [1] is the first computer chess player to win a game, and the first to win a match, against a reigning world champion under regular time controls. Deep Blue’s victory was considered a milestone in the history of artificial intelligence.
-
AlphaGo [2] is a computer Go player that defeats a professional human Go player, and defeats a Go world champion for the first time.
-
AlphaFold2 [3] provides a solution to a 50-year-old grand challenge in biology, determining protein structure given its sequence.
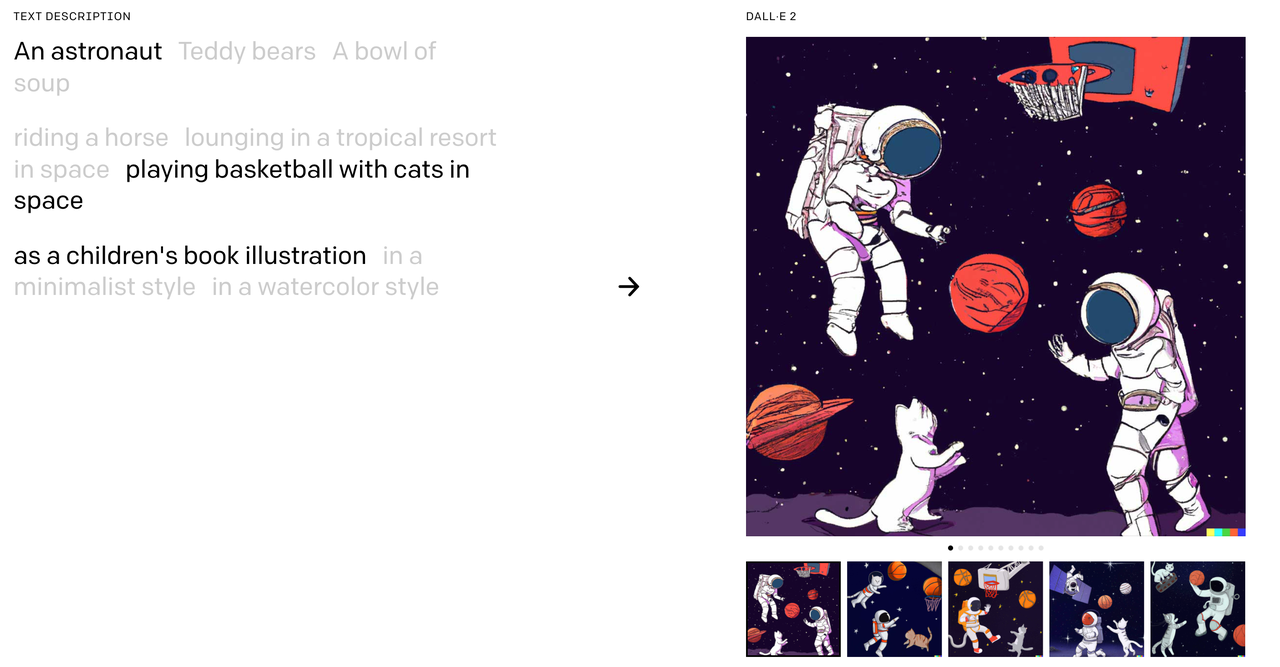
- DALL·E 2 (2022) [4] is one of the largest AI systems that can create realistic images and art from a description in human-readable language.
What is Artificial Intelligence?
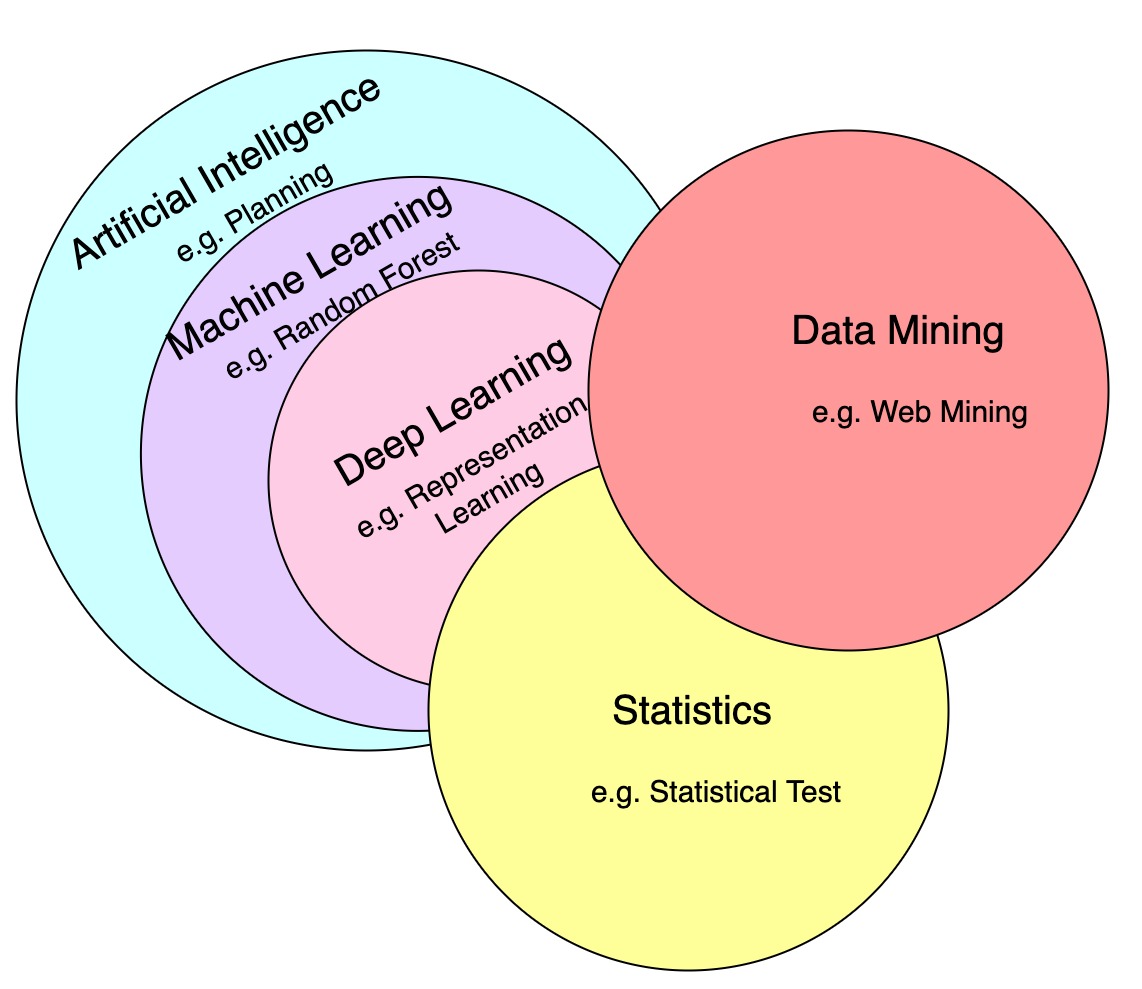
Many words describe areas closely related to AI, sometimes they could be called AI generally, but we illustrate their relationships below. (examples shown in each level are disjoint examples from the overlapping subjects):
-
Artificial Intelligence is a generic word that represents intelligence demonstrated by machines which include a broad set of methods from traditional reasoning and planning methods to modern machine learning approaches.
-
Machine Learning is the study of computer algorithms that can improve automatically through experience and by the use of data. It is seen as a part of artificial intelligence.
-
Deep Learning is one type of machine learning methods that leverages artificial neural networks with back propagation for representation learning.
-
Statistics is the discipline that concerns the collection, organization, analysis, interpretation, and presentation of data, which shares great overlaps with AI in terms of methodologies.
-
Data Mining is a process of extracting and discovering patterns in large data sets involving methods at the intersection of AI, statistics, and database systems (access and storage of data).
What does AI bring to the scientific Community?
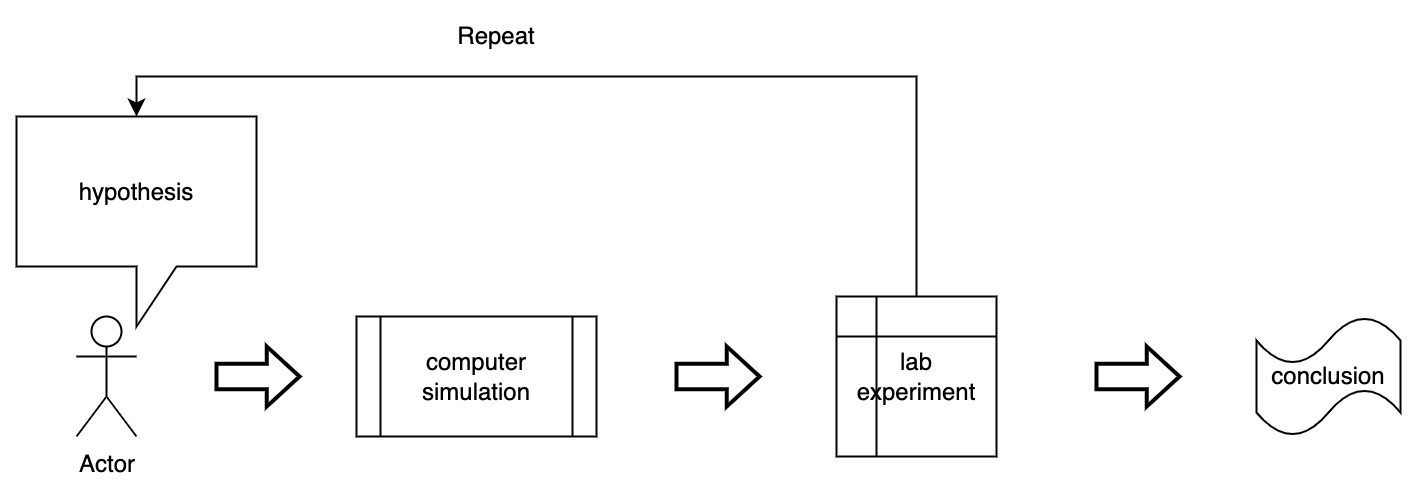
Traditional Discovery Process in Science (a day of a scientist)
-
Goal - Drug design (AI can help in different phases of drug design)
-
Hypothesis - Hand-crafted design (AI can help search the vast chemical space and propose drug candidates)
-
Simulation - Computer simulation (AI can accelerate and improve the accuracy of computer simulation)
-
Experiment - lab experiment (AI can guide lab experiment design)
-
Result analysis - Statistical analysis (AI can analyze high-dimensional data)
-
Repeat
-
Conclusion & Finding
| Goals | Traditional Methods | AI-Based Methods |
|---|---|---|
| Drug Design | - Error-prone and intuition-based workflows | - AI aided rational drug design |
| Virtual Screening | - Docking (based on physical scoring functions) - 2D/3D/based on pharmacophore similarity search |
- Neural network-based scoring functions - Generative models |
| Lead Optimization | - MD-based free energy calculation with empirical force field - Wet-lab experiment |
- AI-predicted binding - Simulation with more accurate force fields developed with neural networks affinity |
| Drug Synthesize | - Error-prone experiments to find optimal synthesis route and reaction conditions | - Retro-synthesis analysis by AI models - AI predicted reaction outcomes - Automated wet-Lab experiment |
| ADMET | - Experiments | - AI-based prediction models |
Even decades ago, AI was widely used in the scientific community
- Example: principal component analysis/PCA, linear regression, Kalman Filter, clustering algorithms, etc.
Data analysis empowered by modern AI
-
Why has AI become so popular recently? (What changed the game?)
-
Accumulated Big Data
-
Advanced Algorithms (especially Rising of Deep Learning)
-
Improved Computing Power and Storage
-
-
What is data? Data are individual facts, statistics, or items of information, often numeric. In a more technical sense, data are a set of values of qualitative or quantitative variables about one or more persons or objects.
-
What is learning? Learning refers to machine learning, which is the study of computer algorithms that improve automatically through experience.
-
Why do we learn from data? Learning from accumulated data enables us to analyze data and execute certain tasks.
-
What are common tasks that could be solved by AI?
-
Predictive tasks refer to predicting the value or status of something of interest.
- Example: predict whether an image is a cat or dog.
-
Generative tasks refer to generating new data by learning from existing data.
- Example: generate new drug-like molecules.
-
Decision-making tasks refer to making decisions based on the information provided.
- Example: decide on trading strategies for the stock market.
-
-
How do we learn from data? Two essential components of learning from data are (1) data and (2) learning.
-
Data includes two main components, data points, and labels, data points refer to the single instances of facts, statistics, or items of information, while labels are meaningful and informative tags for the data points. (Note the labels are often expensive to obtain, thus most of the data are unlabelled)
-
Data Points:(X) cab be in any format, text, image, graph, etc.
- Example: images of cats and dogs
-
Labels: (Y) are informative tags
- Example: cat or dog
-
-
Learning essentially involves three main broad categories, Supervised Learning, Unsupervised Learning, and Reinforcement Learning. We include an additional learning diagram, Active Learning, which is commonly used in scientific discovery.
-
Supervised Learning learns with labeled data, usually, for predictive tasks, a special case is Semi-supervised Learning where only partial data are labeled, since labels allow us to directly assess the predictive performance of a machine learning model in certain circumstances.
- Example: predicting molecular properties from molecular structures
-
Unsupervised Learning learns with unlabeled data and discovers patterns from data, usually for clustering, dimensionality reduction, and visualization tasks. Another rising topic, Self-supervised Learning, also requires no labeled data by training models to predict “missing” or masked parts of the input, and it focuses more on predictive tasks similar to supervised learning.
- Example 1: clustering galaxy images with similar patterns
- Example 2: clustering molecule conformations with similar patterns which reduces the workloads for MD analysis
-
Reinforcement Learning concerns how intelligent agents ought to take actions in an environment in order to maximize the notion of cumulative reward.
- Example: AI agent for nuclear fusion reactor control
-
Active Learning is a learning algorithm that can request labels (or propose experiments) that provide information that be most useful for it to improve predictive performance. It is also referred to as optimal experimental design.
- Example: uncertainty estimation to guide the experiment/data collection
-
-
-
How do we collect or represent data?
-
Representation Learning is a set of techniques that allows a system to automatically discover the representations needed for feature detection or classification from raw data. This replaces manual feature engineering and allows a machine to both learn the features and use them to perform a specific task.
-
Tabular Representation (columns are features)
- Example: weather data stored in tables
-
Grid Representation (stored in grids)
- Example: cell images
-
Sequence Representation (stored in sequences)
- Example: genes
-
Graph Representation (stored in nodes and edges)
- Example: molecular graphs
-
Geometry Representation (stored in 3D geometries)
- Example: protein structures
-
-
-
Could we generate new data?
-
Generative Modeling learns the distributions of observed samples and generates unseen samples.
- Example: goal-oriented molecule generation, protein conformations sampling
-
Mindsets for AI
Key abilities of AI
-
Automated feature learning. Instead of traditionally manual design of features for various tasks, AI takes data in raw formats and automatically learns the features while optimizing the task objectives.
-
Learning from big data. AI can learn from the accumulated “big” data in many domains that traditional methods are not capable of.
-
Inductive bias (e.g. symmetry preservation). AI models are flexible and can be designed to respect natural laws such as symmetries.
-
Generalizability (to unseen data). After training the AI model, it is expected to generalize to new scenarios and unseen data. In some scenarios, it is also expected to generalize to new dataset or similar task after training with one general dataset or task.
-
Fit high-dimensional function. AI models can fit complex functions, such as free energy surface, Schrodinger equation, etc.
-
Differentiable programming. AI brings a new wave of differentiable programming and pushes forward the development of many tools for automatic differentiation, such as PyTorch, Tensorflow, Theano, etc.
Limitations of AI
-
Overfitting. AI models sometimes overfit into the given data set which hinders their abilities to generalize to other datasets.
-
Data requirement. No free lunch, AI models usually rely on large-scale datasets.
-
Computational cost. AI models usually consume plenty of computational resources, especially with the growth of the model and data sizes.
-
Explainability. AI models usually have poor explainability and are thus considered “black-boxes”, though it is an active area of research.
How does AI work?

Typical pipeline
-
Problem Formulation is an essential step to formulate a problem in a “machine learning language”
-
What is the input? What is the output? What is the task?
-
Input: images of cats and dogs;
-
Output: whether the images are cats or dogs;
-
Task: Predictive or Classification task.
-
-
What is the input representation? What is the output representation? What is the objective function?
-
Input representation: Images.
-
Output representation: Scalars.
-
Objective function: measurement between the predicted labels and ground truth labels (cross-entropy loss is very common for classification tasks)
-
-
-
Data Preparation/Processing is conducted after problem formulation. The data could be accumulated, or specifically curated for the formulated problem. It is utilized to collect and manipulate the data to produce meaningful information under the formulation of the problem.
-
Data Representation is another important step to represent data in a machine-readable (or numeric) format. The type of representation is also critical to model choice and which type of specific information it aims to capture.
-
Model Choice is another important step in the pipeline which determines the key model used to learn to fulfill the task. It mainly includes traditional machine learning models and deep learning models. In addition to the model choice itself, for a model to learn from data efficiently, we often need to design a measurement or objective function such that the model can be aware of how good or bad it is performing, then an optimizer is needed to adjust the model accordingly.
-
Traditional ML Models (Modeling data w/ limited structured inductive bias (i.e. data is not always assumed to be in certain structure like graph))
- Random Forests, Support Vector Machine, Gradient Boosting, etc.
-
Deep Learning Models (Modeling data w/ structured inductive bias)
-
Multi-layer Perceptron (MLP) models all types of data (without structure inductive bias)
-
Convolutional Neural Network (CNN) models grid data
-
Recurrent Neural Network (RNN) models sequence data
-
Graph Neural Network (GNN) models graph data
-
Transformer models sequence data originally, but later adapted to model all types of data
-
-
Objective/Loss Function
-
Mean-squared error loss for regression task
-
Cross-entropy loss for classification task
-
More to read: Common Loss functions in machine learning [5]
-
-
Optimizer is the algorithm used to minimize the objective/loss function and update the parameters of the machine learning model. More to read [6]
- Common optimizers include SGD, Adam, RMSProp, etc.
Evaluation/Result Analysis is conducted to evaluate the performance of the model and provide feedback to improve the whole pipeline.
-
Training/Validation/Testing Set Evaluation (Common procedure: tuning parameters on the training set, select the parameters that have the best performance on the validation set and report the result on the testing set to mimic the real-world scenario when unseen/new data come as the testing set)
-
Evaluation Metrics measure the performance of the model.
-
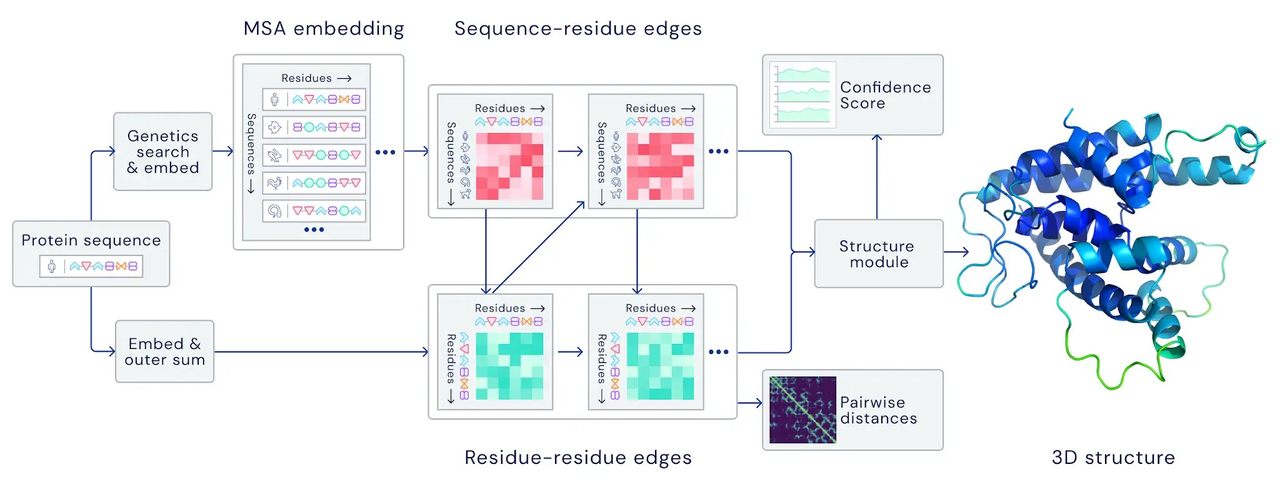
Real-world Example (Protein Structure Prediction - Alphafold2)
-
Problem Formulation
-
Input: protein sequence (a sequence of N amino acids)
-
Output: protein structure (coordinates of amino acids in 3D space -> (N \times 3))
-
Task: predictive or regression task
-
-
Data Preparation
-
Accumulated protein structures from Protein Data Bank (PDB) (sequence, structure pairs)
-
Searching Multiple Sequence Alignment (MSA) for each protein sequence (demonstrated to help with learning coevolutionary information)
-
Accumulated protein templates (existing templates for some proteins)
-
-
Model Choice - Deep Learning Models
-
Transformers in modeling MSA embeddings and producing pairwise and single-sequence features
-
Transformers in modeling pairwise and single-sequence features and output structures
-
-
Objective Function
- Cross-entropy loss, mean-squared-error loss, etc.
-
Optimizer - Adam Optimizer
-
Evaluation/Result Analysis
-
TMScore, lDDT (measurement between two structures)
-
plDDT, pTMScore (predicted lDDT/TMScore for uncertainty estimation)
-
AI Systematic Learning Roadmap
-
Specialized/Advances Topics
References
[1] Wikipedia Contributors. Deep learning, 05 2019.
[2] DeepMind. Alphago: the story so far, 2016.
[3] The AlphaFold Team. Alphafold: a solution to a 50-year-old grand challenge in biology, 11 2020.
[4] OpenAI. Dall·e 2, Apr 2022
[5] Ravindra Parmar. Common loss functions in machine learning, 09 2018.
[6] Sebastian Ruder. An overview of gradient descent optimization algorithms, 01 2016.